Real-world MLOps for batch inference with model monitoring using Amazon SageMaker
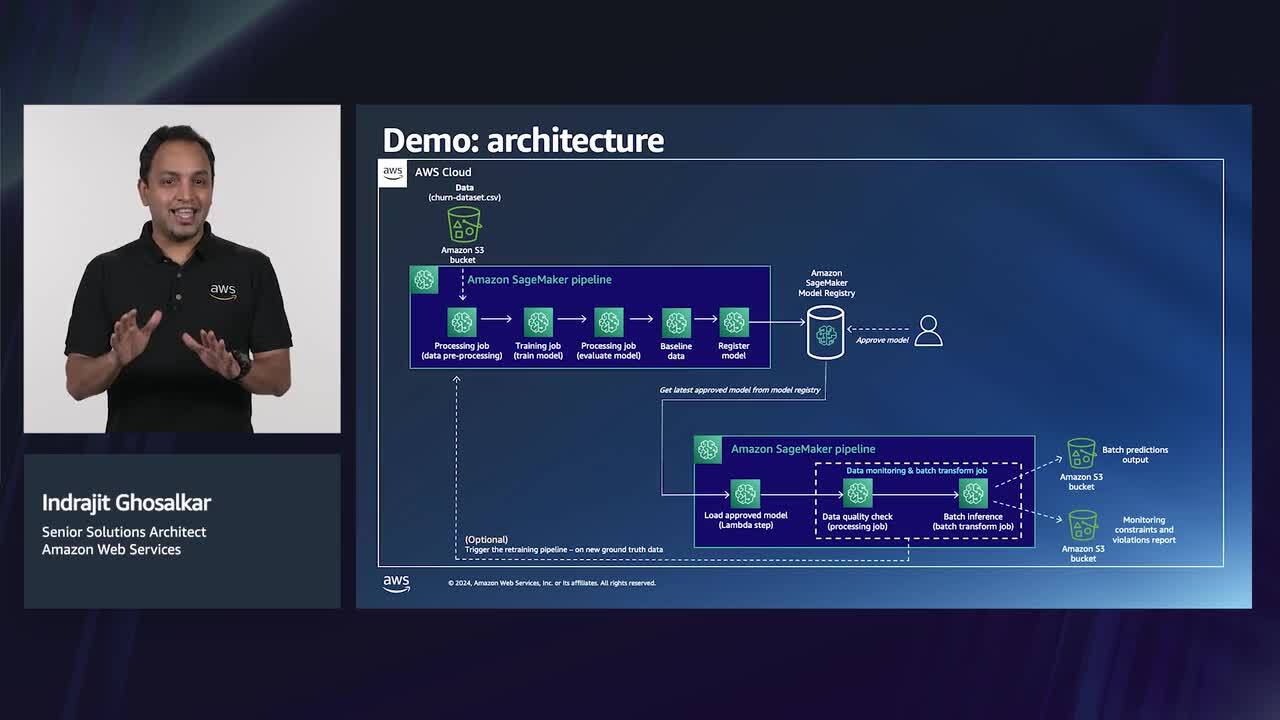
Maintaining ML workflows in production is not easy, as there is a need to create continuous integration and continuous delivery (CI/CD) pipelines for ML code and models, manage model versioning, and monitor for data and concept drift, as well as model retraining. In addition, there is a manual approval process to ensure new versions of the model satisfy both performance and compliance requirements. Join this session to learn how to create ML workflows for batch inference to automate key steps such as job scheduling, model monitoring, retraining, and registration with Amazon SageMaker. Discover the best practices in MLOps and how to integrate them with your existing CI/CD and IaC (Infrastructure as Code) tools. We will share key approaches you can use to mitigate challenges and common pitfalls when adopting MLOps practices. The session concludes with guidance on how to reduce the complexities and costs associated with running and maintaining batch inference workloads in production.
Speaker: Indrajit Ghosalkar, Senior Solutions Architect, AWS