Deploying a Text to Image Model with Amazon SageMaker and Amazon Rekognition (Level 200)
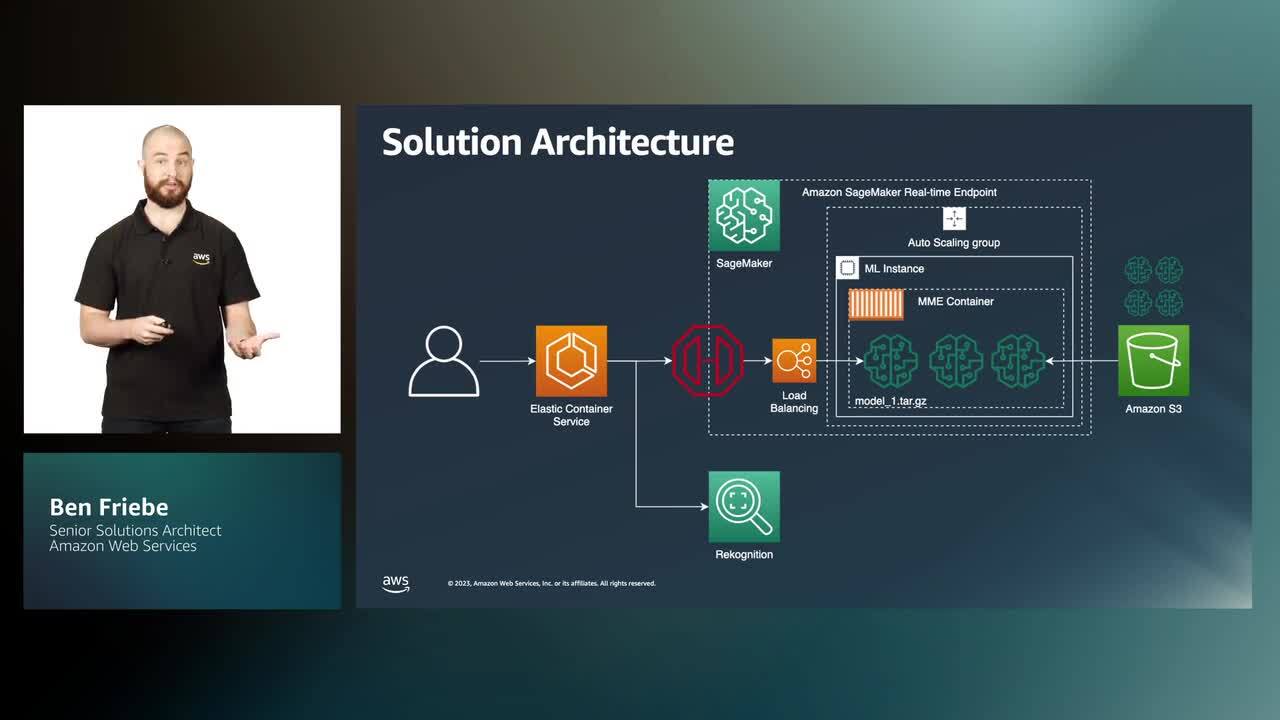
Join this session to learn how global visual communications platform Canva built their new text-to-image functionality with Stable Diffusion on Amazon SageMaker, enabling them to scale the text-to-image feature to 100 million users quickly in less than 3 weeks. We dive deep into the architectural framework behind the end-to-end solution, how to remove heavy lifting from each step of the ML process, making it easier to develop high-quality models, rapidly roll out innovate new features to users and scale for future growth. We also share how Canva leverage Amazon Rekognition, which offers pre-trained and customizable computer vision (CV) capabilities to extract information and insights from images and videos. Learn how this solution enabled them to build user trust, safety and improve productivity, as manual moderation would have required Canva to deploy hundreds of moderators round the clock. Download slides »
Speakers:
Ben Friebe, Senior ISV Solutions Architect, AWS
Greg Roodt, Head of Data Platforms, Canva
Duration: 30mins