Customize and improve your document extraction with machine learning (Level 300)
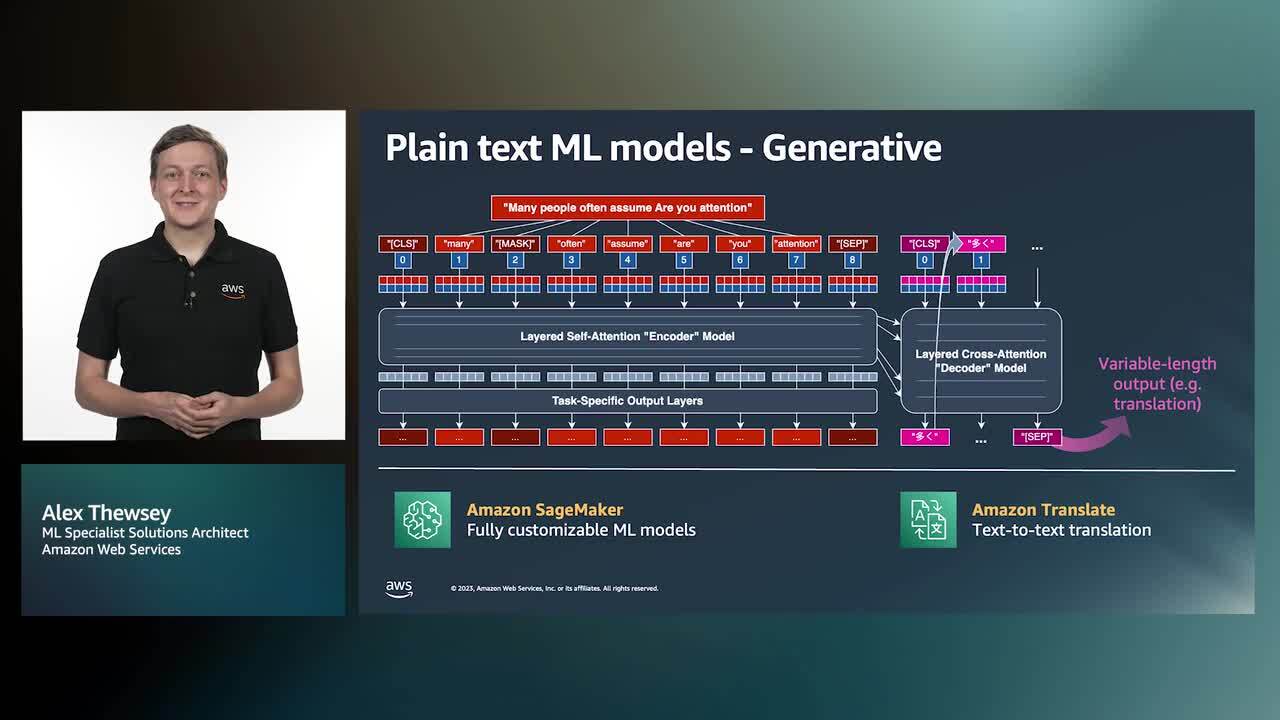
Documents come in various file types, varied formats, and contain valuable information. The extraction and processing the documents can be time consuming, prone to error, and costly. In this session, we share the options on how to easily extract information from complex content in any document format. including PDFs or scanned images with AWS. Learn how to tune and customize that extraction with ML including common OCR error patterns and re-structuring output data. The session covers different patterns and tools on AWS to help across all stages of the pipeline from initial image pre-processing, through to process automation or intelligent search, and online human review, taking into account the complexity of your use case and ML maturity in your organization. Download slides »
Speaker: Alex Thewsey, ML Specialist Solutions Architect, AWS
Duration: 30mins