Build, deploy, and scale data-intensive workloads with Data on Amazon EKS
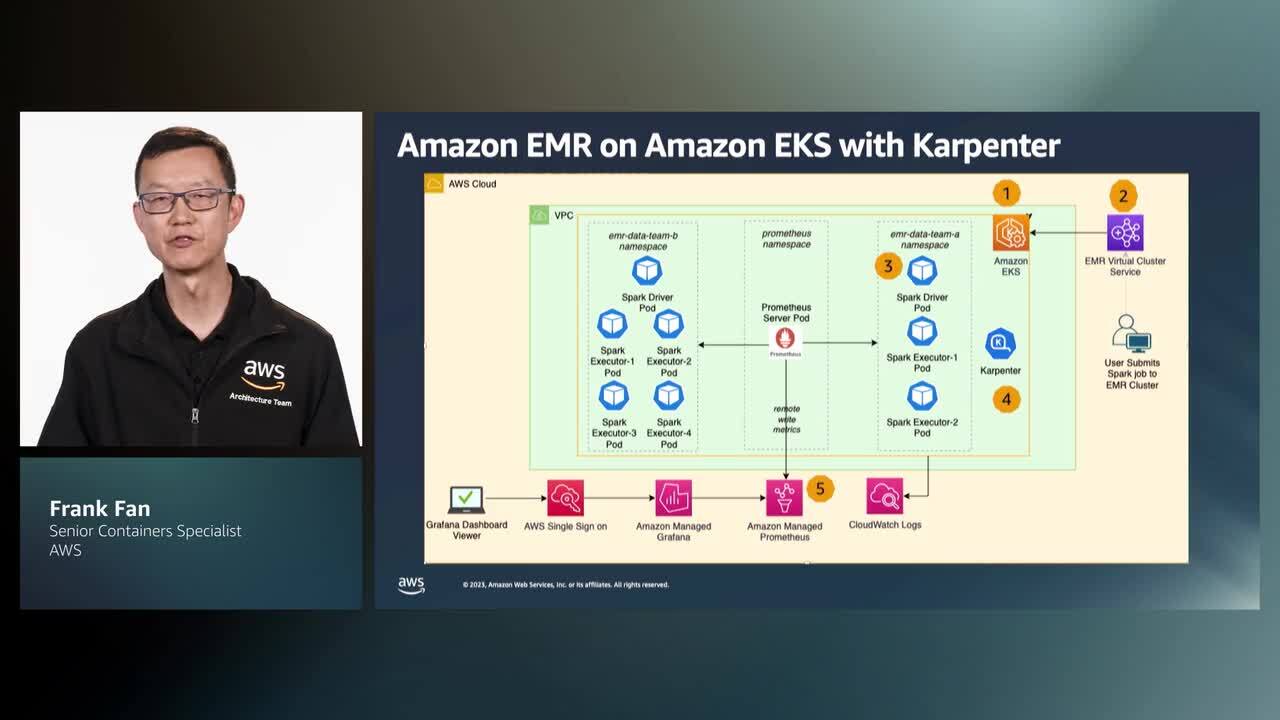
Kubernetes has emerged as a popular platform for those looking at running data and machine learning workloads due to improved agility, scalability, and portability. However, deploying and scaling data workloads on Kubernetes remains a challenge for many customers. There are many conflicting tools with varying levels of maturity, integration, and compatibility with existing platforms. These workloads are often high-throughput, compute-intensive, and critical to business operations, requiring a proper configuration to support their requirements. This session showcases how to leverage Data on EKS (DoEKS) to simplify and speed up the process of building, deploying, and scaling data workloads on Amazon EKS. DoEKS builds on the foundation of the Amazon EKS Blueprints project and incorporates guidance and tools to support the unique challenges and requirements of data-related workloads on Kubernetes. We dive deep into the best practices, examples, and architectures aimed at making it easier to build, deploy, and scale data-intensive workloads on Amazon Elastic Kubernetes Service (Amazon EKS), enabling you to simplify data processing and analysis to extract valuable insights and drive value creation, provide a competitive edge, and enhance customer experiences. Download slides », Download demo »
Speaker: Frank Fan, Senior Containers Specialist Solutions Architect, AWS