Processing Big Data with Hadoop, Spark, and other frameworks in Amazon EMR (Level 300)
Fill form to unlock content
Error - something went wrong!
Register Here
Thank you!
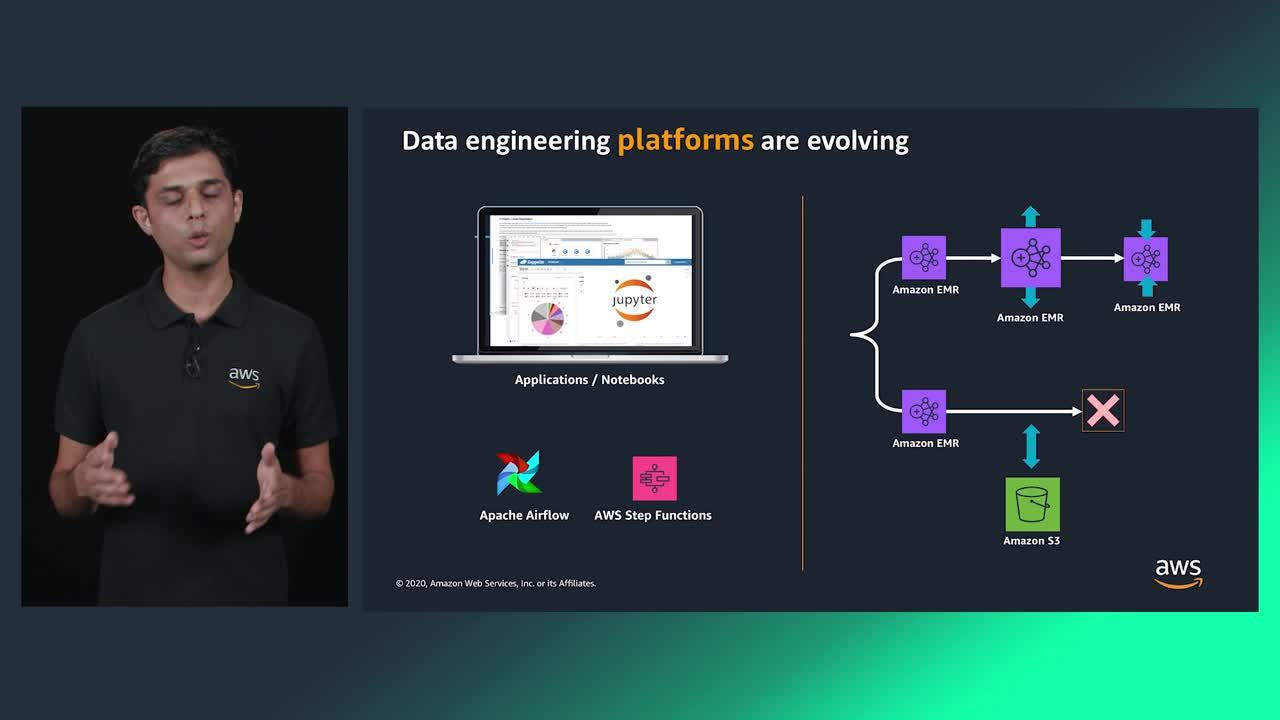
Amazon EMR provides a managed Hadoop framework that makes it easy, fast, and cost-effective to process vast amounts of data. You can also run other popular distributed frameworks such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. EMR Notebooks, based on the popular Jupyter Notebook, provide a development and collaboration environment for ad hoc querying and exploratory analysis. In this session, learn how data pipelines are currently evolving to be more elastic and scalable, and how Amazon EMR securely and reliably handles a broad set of big data use cases, including data transformations (ETL) and machine learning.
Speaker: Aneesh Chandra PN, Big Data Solutions Architect, AWS