SQL-based stream processing at scale with Apache Kafka and Apache Flink
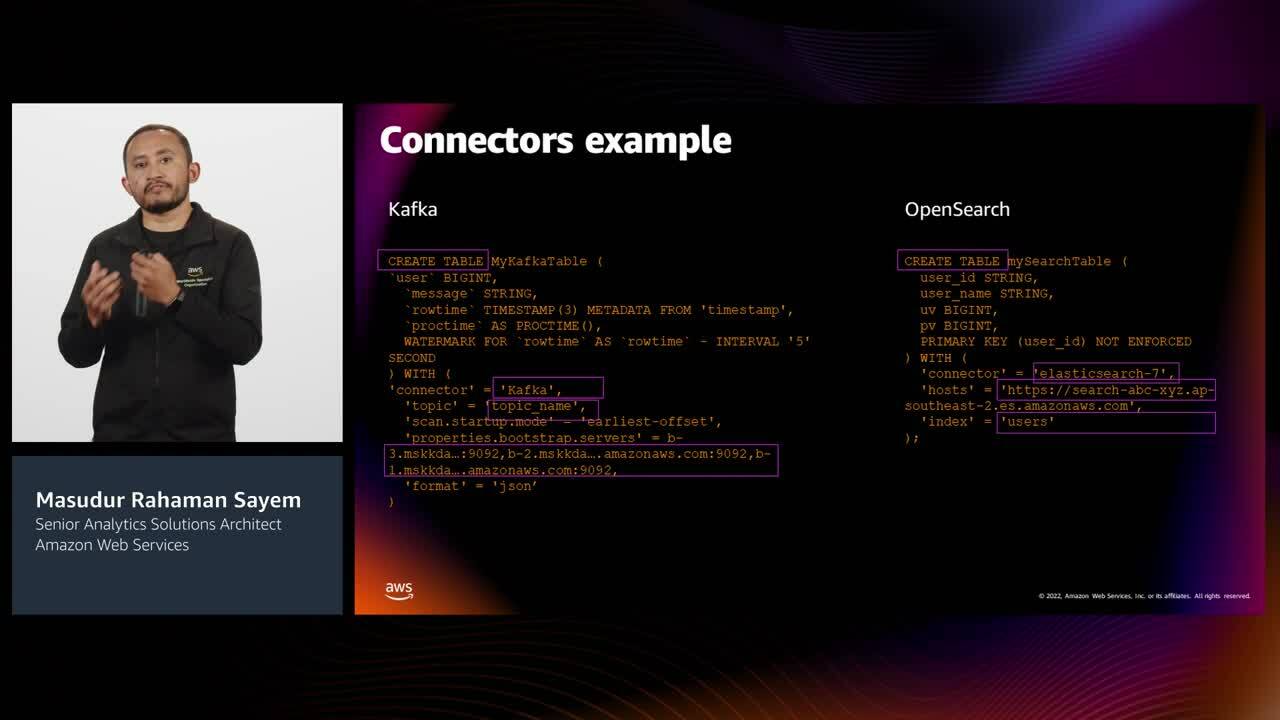
We are witnessing a rapidly growing interest in real-time data processing with streaming data infrastructures like Apache Kafka and Apache Flink. However, streaming data analysis requires a unique skill, such as knowing Java or Scala APIs, and understanding stream processing concepts like window, time, and state which are complex. On the other hand, SQL is a widely used language for data processing and is easy to learn. This session discuss how you can use SQL to process real-time data from Apache Kafka using Amazon MSK and Amazon Kinesis Data Analytics for Apache Flink.
Speaker: Masudur Rahaman Sayem, Senior Analytics Solutions Architect, AWS
Download slides »