Building a high-performance, transactional serverless data lake on AWS
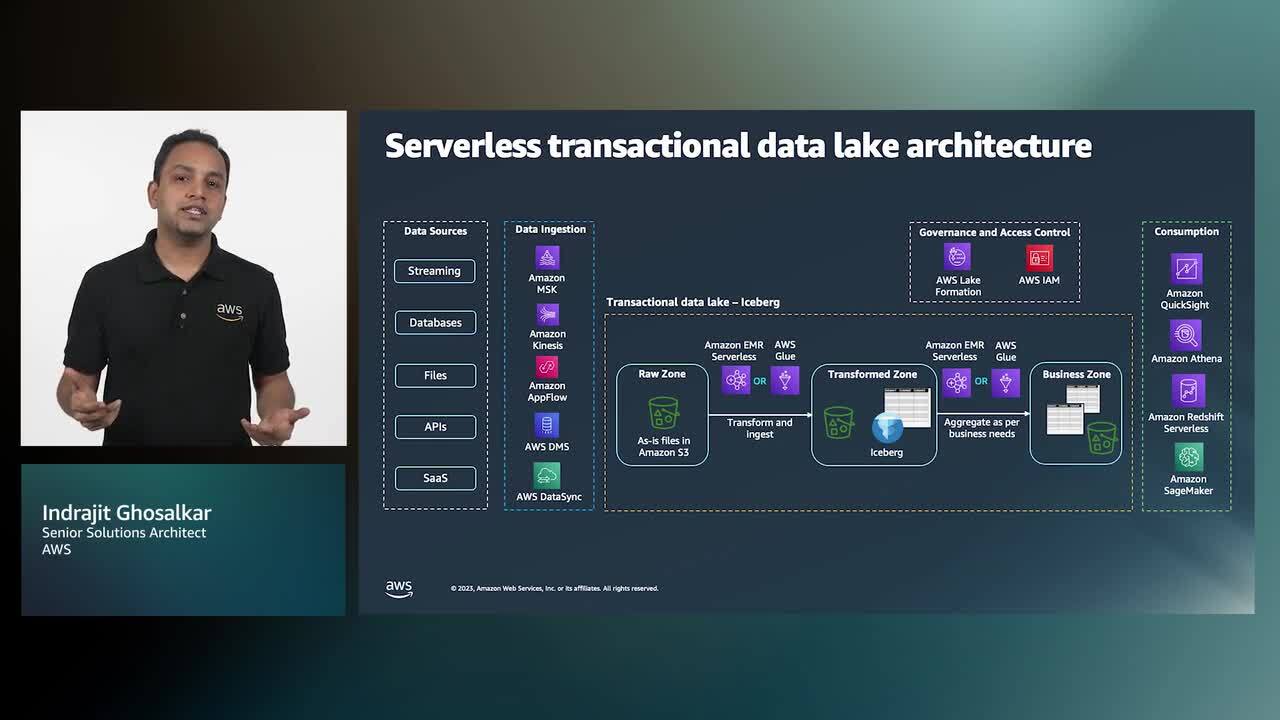
Data lake is a central repository to store structured and unstructured data at any scale and in various formats. However, tasks such as updating, deleting a subset of identified records from the data lake, and making concurrent changes can be time consuming and costly. In this session, we explore the most common transactional data lake formats. We will take real-world examples to demonstrate how to build high-performance transactional data lakes to run analytics queries that return consistent and up-to-date result with analytics and serverless solutions including Amazon Apache Iceberg on EMR Serverless and Amazon Athena. The session addresses how to support ACID (Atomicity, Consistency, Isolation, Durability) transactions in a data lake, time-travel, schema / partition evolution and purging of individual records to meet regulatory and compliance needs as data lake use cases grow. Download slides », Download demo »
Speaker: Indrajit Ghosalkar, Senior Solutions Architect, AWS