Intelligent document processing Building higher accuracy document automation at scale (Level 200)
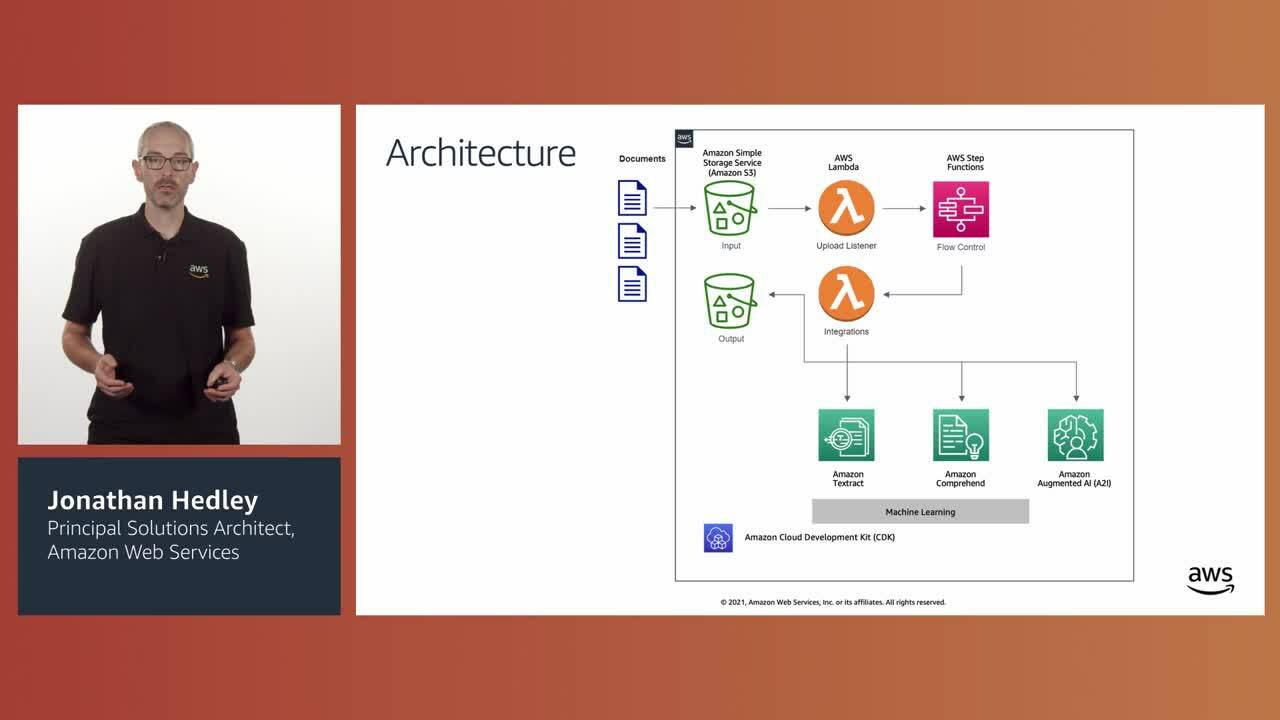
Organizations have millions of physical documents and forms that hold critical business data. These documents, such as insurance claims or loan applications, have structured and unstructured data that are either extracted by humans or by rule-based systems which are not easily scalable, have high costs, and could produce low-accuracy extraction results. In this session, learn how to use Amazon Textract, Amazon Comprehend, and Amazon Augmented A2I to extract structured data, redact sensitive information, and deploy your automated document processing workflow into production, at scale.
Jonathan Hedley, Principal AI/ML Specialist Solutions Architect, AWS